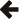


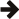
The performance situation for UTF transcoding is complicated, and so bears some discussion. All the charts below were generated using Google Benchmark, built with GCC on Linux.
Here are the relative timings for UTF-8 to UTF-16 transcoding, using various
methods (smaller is better). The input was around half a megabyte of text from
Wikipedia. "Iterators" is using std::copy from
utf_8_to_16_iterator
to a pointer; "Algorithm std::back_inserter" is using transcode_to_utf16() in the SIMD code path, and
outputting to a std::back_insert_iterator; "Algorithm using
SIMD" is using transcode_to_utf16()
from pointer to pointer in the SIMD-using code path; "Algorithm no SIMD"
is using transcode_to_utf16()
from pointer to pointer in the non-SIMD code path; and "ICU" is is
using UnicodeString::fromUTF8().
The ICU performance is shown as something of a baseline, given the ubiquity of ICU's use in Unicode-aware programs. Note that ICU does not have convenient APIs for doing transcoding to any format but UTF-16.
There are four take-always from this chart (and in fact all the other transcoding data):
A major reason for the performance differences is that the fastest algorithms are able to write out chunks of their results all in one go (up to 16 at once in the SIMD paths of the transcode algorithms). Needing to branch on each output code unit as in the "Iterators" and "Algorithm std::back_inserter" cases is much slower. One implication of this is that if you're doing a lot of work with each code unit or code point produced, you're probably doing a lot of branching in the work, and so the gains of using the high-performance methods above will be lost. Specifically, using transcoding iterators to complicated Unicode algorithms like the Bidirectional Algorithm do not result in much (if any) performance loss.
These are relative timings for UTF-8 to UTF-32 transcoding. It is in the same scale as the chart above.
Again, you can see very similar relationships among the different transcoding methods, except that the iterator method is a lot faster.
Note that the SIMD algorithm is quite fast. It — and all the SIMD code — was originally developed by Bob Steagall, and presented at C++Now in 2018. Thanks, Bob!
Here are the relative timings for NFC normalization of UTF-8 strings (smaller
is better). The input was around half a megabyte of text from Wikipedia. "Algorithm
with back-inserter" is using normalize<nf::c>(as_utf32(input),
utf_32_to_8_back_inserter(output))
-- this is the slowest code path, since it uses a back-inserter; "String
append" uses normalize_append<nf::fcc>(),
with pointers used for input and output; "ICU" is the UTF-8-specific
normalization algorithm from ICU; and "ICU UTF-16" is the UTF-16
normalization algorithm from ICU. "ICU UTF-16" normalizes in UTF-16,
not UTF-8; it is shown here because it is the fastest code path for ICU.
These charts represent four scenarios: half normalize European languages (English and Portuguese); half normalize non-European languages (Chinese, Korean, Hindi, and Russian); half normalize NFC-normalized input; and half normalize NFD input.
Normalization of NFC, European script text:
Normalization of NFC, non-European script text:
Normalization of NFD, European script text:
Normalization of NFD, non-European script text:
Not surprisingly (given the earlier results above), using a back-inserter in "Algorithm with back-inserter" is quite slow. The other code paths are all able to output long sequences of already-normalized code points in runs, and the use of a back-inserter interrupts this important optimization. In fact, since the same transcoding iterator unpacking logic from the transcoding views is applied to the normalization algorithms, the only functional difference between "Algorithm with back-inserter" and "String append" is the use of the back-inserter.
The best case for Boost.Text is normalizing to NFC in European text that is already NFC. Given the common use of NFC and UTF-8, this is probably the most relevant case for many users. In this case, Boost.Text is factors faster than ICU's UTF-8 code path, and a bit faster than ICU's much faster UTF-16 code path. The remaining charts show that Boost.Text does worse with non-European text, and also worse with text that starts out NFD. In every case, Boost.Text is faster than the UTF-8 ICU code path.
These are just like the NFC chart, both in meaning and results; they are shown here for completeness. Note that the FCC normalization form is what Boost.Text uses internally in all the text layer types. See Unicode Technical Note #5 for details.
Normalization of NFC, European script text:
Normalization of NFC, non-European script text:
Normalization of NFD, European script text:
Normalization of NFD, non-European script text:
These are the charts for normalizing to NFD. The meaning of the labels in each one is the same as they were in the NFC charts.
Normalization of NFC, European script text:
Normalization of NFC, non-European script text:
Normalization of NFD, European script text:
Normalization of NFD, non-European script text:
rope is 8ns with non-atomic
ints, vs. 9-10ns with atomic ints. Comparison was done on MacOS.